Spark V2 连接器
简介
Apache Spark 是一种用于大数据工作负载的分布式开源处理系统。它使用内存中缓存和优化查询的执行方式,可针对任何规模的数据进行快速分析查询。
Apache Spark 提供了广泛的数据源支持,可以与多种数据存储和格式进行交互。其中 Spark v2 连接器的目的就是为 Spark 提供 SequoiaDB 数据源支持,让 Spark 可以直接使用 SequoiaDB 中的数据进行数据计算。
Spark v2 连接器是针对 Spark 2.x 版本的连接器实现。连接器实现了 Spark 最初的 Data Source 接口,即 Spark Data Source V1 API。
实现机制
Spark Data Source API V1 为我们抽象了一系列的接口(定义在org.apache.spark.sql.sources.interfaces.scala 文件中),实现对应的接口可以提供不同的数据源操作能力。
- 定义一个类
com.sequoiadb.spark.DefaultSource并实现DataSourceRegister用于注册数据源,将其打包为 jar 并放入 spark 的 jars 目录中。Spark 启动时会自动加载自定义的 jar。 - 启动 spark-sql 后通过如下语句关联 sdb collection:
create table xxx
...
using com.sequoioadb.spark
options(
`host` 'xxxx:xxxx',
`collectionspace` 'xxx',
`collection` 'xxx'
)Spark V2 连接器实现的数据操作接口
实现表创建接口
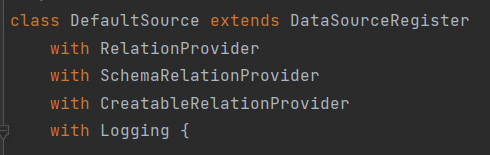
DataSourceRegister:数据源注册RelationProvider:创建表时不提供表结构让 Spark 根据数据进行推断
create table xxx
using com.sequoioadb.spark
options(
`host` 'xxxx:xxxx',
`collectionspace` 'xxx',
`collection` 'xxx'
);SchemaRelationProvider:创建表时提供表结构
create table xxx (
`id` INT,
...
)
using com.sequoioadb.spark
options(
`host` 'xxxx:xxxx',
`collectionspace` 'xxx',
`collection` 'xxx'
);CreatableRelationProvider:create table as select
create table xxx
using com.sequoioadb.spark
options(
`host` 'xxxx:xxxx',
`collectionspace` 'xxx',
`collection` 'xxx'
) as select * from xxx;实现表操作接口
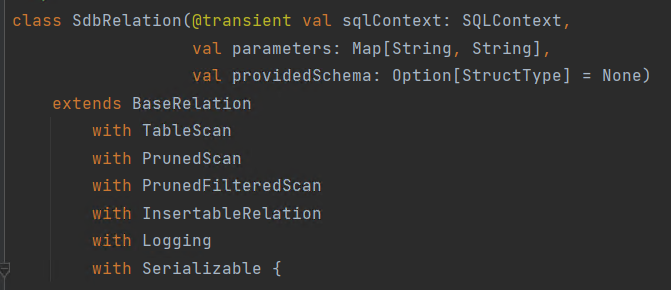
BaseRelation:提供表结构TableScan:查询接口 select * from xxx;PrunedScan:列裁剪 select a, b from xxx;ProunedFilteredScan:条件下压 select * from xxx where xxx;InsertableRelation:数据插入 insert into xxx values xxx;